
What is Continuous Integration?
19 May 2021

Continuous Integration (CI) appears more and more in the context of software development and seems to be a relatively new approach. The term, however, dates back to the early 90s, when it was used by Grady Booch (one of the founders of the UML language) in the book “Object Oriented Design: With Applications”. CI owes its further development to the spread of agile software development methodologies, in which it plays one of the key roles.
This article tries to answer the question: “What is continuous integration and how does it affect the quality of your applications”.
What is CI
Continuous integration is an appropriate approach to software development, where members of the development team often integrate the results of their work in the form of the source code of the application being built. Typically, each member of the development team integrates their changes to the application’s source code with the work of their teammates at least once a day. Each such integration is verified by the process of automatic build and automatic tests in order to detect integration errors as quickly as possible. It is believed that this approach significantly reduces integration problems and enables development teams to build consistent software faster and facilitate project management.
CI Tools
The idea of continuous integration is based on the use of tools that support this process.
One of these tools is the source control management (SCM) system also known by other names such as: configuration management system, version control systems, code repositories. This software is used to track changes mainly in source code, and supports development teams in merging changes made to files by many people at different times. There are many different systems of this type available today. The most popular are:
- GIT / GITHUB
- BITBUCKET
Other tools related to CI are systems that support building, testing and implementation, facilitating continuous integration and continuous delivery. As with the previous tools, there are also many solutions available here. The most popular are:
- Jenkins
- TeamCity
- Bamboo
- Buddy
- GitLab CI
- CircleCI
- TravisCI
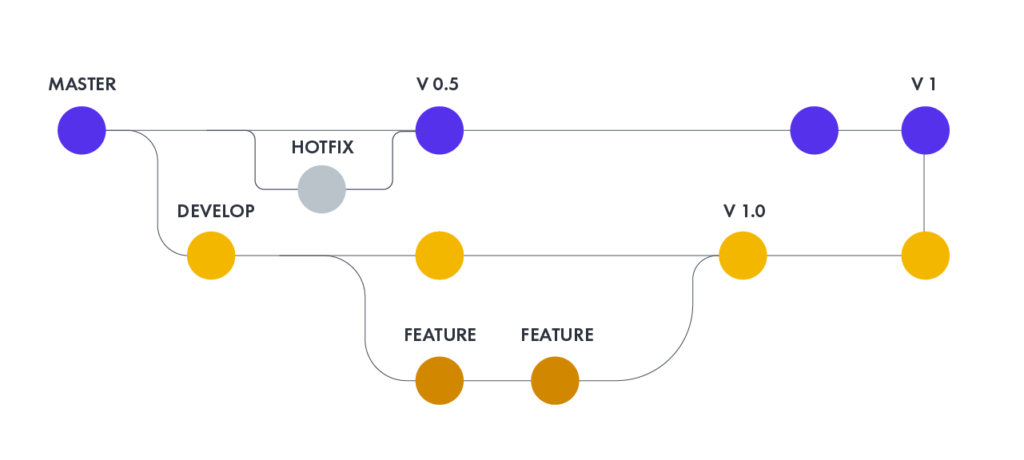
How to create code using continuous integration
The easiest way to explain what CI is and how it works is to show a quick example. Suppose you need to make a change to the source code of the software to add new functionality to it.
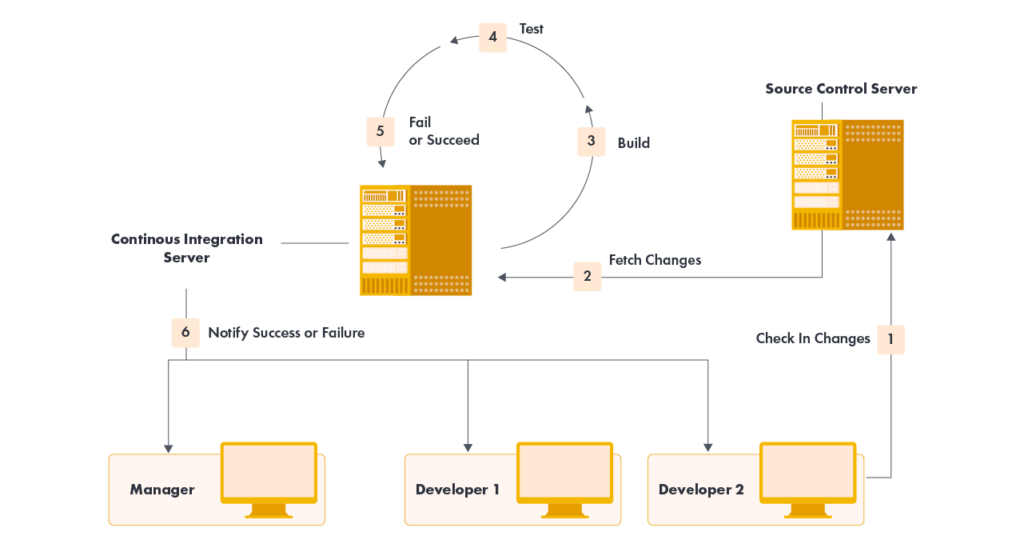
Work on the source code of the software begins with copying the code repository. This is done with the source code management system checking your working copy from the main branch of source code repository.
The source code control system stores all project source code in a repository. The current state of the system is usually referred to as the “master branch”. At any time, the developer can make a controlled copy of the master branch on his computer.
Having a working copy locally one can perform the task of modifying the source code of the software. This will involve both changing the production code and adding or changing automated tests. CI assumes a high degree of use of automated tests. Various types of popular frameworks are most often used to develop tests.
After the modification is completed in the source code, an automated build process is performed on the local workstation. This process takes the source code from the local working copy of the code repository, compiles and combines it with the executable, and runs automated tests. Only when all compilation and automated tests run smoothly the overall compilation is considered correct.
After correct compilation it is possible to commit changes in the repository. The problem is that other members of the development team at the same time can and usually make changes to the main source code branch. Therefore, you first update your working copy to the local repository, making changes and recompiling. If changes made by other team members conflict with your changes, it will fail in build or test. In this case, fix the error and re-compile.
After compiling a properly synchronized working copy, you can finally commit the changes to the main code branch and then update the main code repository.
After updating the main repository, the code is rebuilt, but this time on the integration server. Only when this compilation is successful you can consider that the changes to the source code have been made correctly. There is always a chance that something has been overlooked on the local workstation and the master repository has not been updated properly. Only when the changes made to the main repository build correctly on the integration server, the changes can be considered implemented correctly. This integration build can be done by hand, but most often it is done using the CI build, test and deployment tools mentioned above.
If there is a conflict in changes made to the source code between two developers, usually the conflict is caught when the second developer who approved creates an updated working copy. Otherwise, integration build should fail. Either way, the error is detected quickly. At this point, the most important task is to properly repair the code and get the compilation working properly. In a Continuous Integration environment, you should never have failed integration builds over a long period of time. A good development team should get lots of correct builds daily. Bad compilations can happen very rarely and should be fixed immediately.
As a result, we get stable software that works properly and contains a negligible number of bugs. The development team develops code on a common stable code repository, and frequent code integration takes very little time. You also spend less time looking for errors as CI helps you spot them quickly and efficiently.
Best Practices
This section lists best practices on how to approach implementing continuous integration and automating it. It seems that introducing the process of automating application building is a best practice in itself.
Continuous integration as a practice of frequently integrating new or changed code into an existing code repository should occur frequently enough so that there is no time window between committing code to the master repository and compiling, so that all bugs can be caught by developers and fixed immediately. It is normal and desirable practice to trigger these builds by each commit to a repository rather than a periodically scheduled build.
Another factor is the need for a version control system that supports atomic commits; i.e. all developer changes can be viewed as a single change commit operation.
To achieve these goals, continuous integration is based on the following principles.
Code repository
This practice recommends using a version control system to manage the source code of your software. All files required to build the project must be placed in the repository. The system should be buildable in the new system environment and should not require additional files that are not in the repository. The branching of the source code versions should be minimized. It is preferable to integrate changes rather than maintain multiple versions of software at the same time. The root branch should always be the newest working version of the software. Examples of other branches are bug fixes from earlier production versions or temporary development code.
Automated compilation
Converting source code into a working system can often be a complicated process involving compilation, moving files, loading schemas into databases, and so on. However, like most tasks in this part of the software development process, they can be automated – and therefore should be automated. Manually handling these tasks seems like a waste of time and a breeding ground for unnecessary errors.
Automated build environments are a common feature of systems. Make sure you can build and run your system with these scripts with a single command.
A common mistake is not to include all items in the automatic compilation. The compilation should also include tasks such as retrieving the database schema from the repository and running it in the runtime environment. There should always be a rule by which it is possible to download the source code from the repository and run the system on a local computer or server with one command.
A single command should be able to build the system. Build automation should include integration automation, which often involves deployment in a production-like environment. In many cases, the build script not only compiles binaries, but also generates documentation, web pages, statistics, and application installation versions.
Most programmers use the so-called an integrated development environment (IDE) that has some kind of build management process in it. However, this process is usually proprietary to the IDE and uses it for its operation. Developers can use the IDE to develop and individually compile on their own local workstations. However, it is important to have a master build that can be used on the server and run from properly prepared scripts.
Self-control build
Traditionally compiling means compiling, linking, and all the extra stuff required to run a program. The program may work, but that does not mean it is working properly. Modern static typing languages can catch many errors, but many errors escape this control.
A good way to catch errors faster and more efficiently is to include automated testing in your build process. Of course, testing isn’t perfect, but it can discover a lot of bugs – enough to make these tests useful. In particular, the emergence of agile software development methodologies contributed to the popularization of code self-testing, as a result of which many people saw the advantages of this technique.
To test your code automatically, you need a set of tests that can check a large portion of your code for errors. Tests must be run with a simple command and self-validate. The test suite run result should indicate whether any tests have failed. For the build to run on its own, failing the test should cause the build to fail.
In recent years, many tools and libraries have been created to facilitate the creation and execution of various types of software tests, including unit tests, user interfaces tests, static code analysis, etc.
Of course, you cannot count on testing to detect all errors. The tests do not prove that there are no errors.
Daily changes to the repository
This rule says that every day all members of the development team commit to posting changes to the main code repository.
By regularly approving, each approver can reduce the number of conflicting changes. Checking weekly work runs the risk of conflict with other changes added to the repository by other team members and can be very difficult to resolve. Early, small conflicts in the area of the system cause team members to communicate earlier and more often about introduced changes.
Approving all changes at least daily is generally considered a part of the definition of Continuous Integration. Additionally, it is generally recommended to do an overnight build. It is assumed that the typical frequency of changes to the repository will be much higher. Frequent code approvals in the repository encourage developers to break down their work into small chunks of several hours each. This helps you keep track of changes and provides a sense of progress in building the system.
Compilation after commitments to the repository
After making changes to the code repository, the CI system should build the latest version of the code to verify that it is properly integrated. It is common practice to use automatic continuous integration, although this can be done manually. Automatic continuous integration uses a continuous integration server or a daemon to monitor the version control system for changes and then automatically starts the build process.
The continuous integration server acts as a repository monitor. Each time the commit to the repository completes, the server automatically checks the sources on the integration machine, initiates the build, and notifies the approver (and the team leader, for example) of the build result. Notifications are usually sent by e-mail.
Many teams regularly create builds on a schedule, such as every night. This is obviously not the same as continuous compilation, and is not enough to call it continuous integration. The whole point of continuous integration is finding problems as soon as possible. Overnight builds mean bugs go undetected all day before anyone finds them. Once they have been in the system for so long, it takes a lot longer to find and remove them.
Fix corrupted builds immediately
A key part of implementing continuous compilation is that if a main branch of code repository has a problem and won’t compile, it should be fixed immediately. The whole point of working with CI is that the software is always developed on a stable basis.
“Repairing the build has the highest priority” doesn’t mean that everyone on the team has to stop working to fix the main repository branch. However, it does mean knowingly prioritizing repairing your build as a high priority urgent task.
Often, the fastest way to fix a build is to roll back to the last valid commit from the main repository branch, restoring the system to the last good version. Unless the cause of the failure is immediately obvious, simply restore the main repository branch to its pre-error state and try to diagnose the problem on a copy of the local repository on your development workstation.
When teams introduce CIs, it’s often one of the hardest things to tackle. At an early stage, it may be difficult for your team to acquire the regular habit of working with a major version of a repository, especially if they are working on an existing codebase. Nevertheless, patience and continuous work in this area finally pay off.
Maintain a quick build
The purpose of CI is to provide quick feedback. Nothing discourages you from introducing a CI more than a time-consuming compilation. The guidelines in this regard say that the time of the basic compilation should not exceed 10 minutes.
It’s worth the effort to make it happen, because every minute of reduced compilation time is a minute saved for each developer every time they add code to the main repository branch. Since CI requires frequent approvals, it takes a long time overall.
As it seems, the usual bottleneck is the time of running automated tests. Probably the most important step is to start working on configuring the so-called pipeline. The idea behind the deployment pipeline (the build pipeline or staged build) is that in fact, multiple builds are performed sequentially. Committing to the main repository branch starts the first build. This compilation should be done quickly while reducing the number of tests performed during it. Here, there is a need to balance your debugging and speed needs so that a positive build is stable enough for other team members to work on with the current version of the source code. However, there are further, slower tests you can start doing. Additional machines may run further test routines in the build that take longer to complete.
A simple example of this is the two-step build pipeline. The first step would be to compile and run tests that are more specific unit tests, e.g. with a completely empty database. Such tests can be very quick according to the ten-minute guidelines. However, any errors that involve larger-scale interactions, especially those involving a real database, will not be found. The second stage compilation runs a different set of tests covering the more comprehensive behavior of the system. It may take several hours for this package to start.
If this additional build fails, it may not have the same “stop all” severity, but the team tries to fix such errors as quickly as possible while keeping the major version of the repository branch working.
This example shows a two-stage pipeline, but the basic principle can be extended to any number of consecutive stages. Builds can also be run in parallel. You can introduce all kinds of further automated tests, including performance tests, into the regular build process.
Tests on a clone of the production environment
The purpose of the testing is to correct, under controlled conditions, any problems the system may encounter during production. Much of this is the environment in which the production system will operate. If tests are run in a different environment, any difference creates the risk that what happens during the test will not happen in the production environment.
As a result, you must configure your test environment to reflect your production environment as closely as possible. You must use the same database software, with the same versions, the same version of the operating system. You should put all the appropriate libraries that are in the production environment in the test environment, even if the system does not actually use them. Use the same IP addresses and ports when running on the same hardware.
There are actually limitations. Despite these limitations, the goal should still be to maximize the replication of the production environment and understand the risks that are acceptable for any difference between test and production.
Virtualized environments are increasingly used for the above tests to facilitate the compilation and configuration of test environments. Virtualized machines can be saved with all the necessary elements. After that, it is relatively easy to install the latest build and run the tests. In addition, it allows you to run multiple tests on one computer or simulate multiple machines on a network on one computer.
Access to the latest version
Anyone involved in the development of a given software should have access to the latest version of that software and be able to run it: for demonstration, exploratory testing, or simply to see what has changed on a given day or week. For this purpose, appropriate information about the latest software versions should be placed in a generally accessible place, for example on a suitable server.
Anyone can see what is happening
Continuous integration is about communication, so team members should be able to easily access information about the state of the system and any changes made to it.
One of the most important things to say is the state of the major version. Many CI tools have a built-in website that shows if a compilation is in progress and what was the state of the last revision of the main branch of the code repository. Many teams want to make this even more visible by including a graphical representation of the build process – green lights when the build is running or red if it fails. Red and green controls are a particularly common solution – they not only indicate the status of the compilation, but also its duration. Corresponding graphical information indicates that the compilation was too long.
Of course, the websites of CI servers can contain more information, indicating not only who is building, but also what changes it has made. CI servers also often contain a history of changes, allowing team members to have a good overview of the latest activities in the project and giving the feeling that the system being built is developing at the appropriate pace.
Another advantage of using the CI website is that people who work in locations other than the core team or the team are dispersed, then they can get continuous information on the status of the project. CI servers also often have the ability to aggregate information from multiple projects – ensuring simple and automatic status of various projects.
Automated Deployment
Multiple test environments are needed to perform continuous integration. Since moving systems under construction between these environments can take place many times a day, it should be done automatically. Therefore, it is important to develop scripts that will allow you to easily deploy the application you are building in any environment.
A natural consequence of this is that there should also be scripts that will allow you to deploy the system to the target (production) environment with similar ease. Deploying to production may not be every day, but automatic rollout helps both speed up the process and reduce errors. It is also a cheap option as it uses the same solutions you use to deploy to test environments.
If you are rolling out new system versions to production, you should also consider automated rollback of the new version of the installation. There are installation problems from time to time and it’s good to be able to go back to the previous version quickly. The ability to auto-restore also reduces a lot of stress on deployment, encouraging people to deploy more frequently and thus make new features available to users quickly.

Benefits of CI
Undoubtedly, one of the greatest benefits of running a CI into the software development process is the reduction of the risk associated with building an IT system.
Further benefits of using continuous integration are outlined below:
- integration errors are detected very quickly and are easy to trace thanks to small sets of changes. This saves time and money throughout the life of the project.
- confusion is avoided in the final stage of release of the final version of the software, when necessary corrections are made to the source code.
- in case of errors, if developers need to restore the codebase to an error-free state without debugging, then only a small amount of changes are removed from the repository (as integration occurs frequently)
- “up-to-date” build is always available for testing, demonstration or release purposes
- frequent code checking forces programmers to create modular, less complex code
- faster release of subsequent versions of the software to the end customer
By introducing continuous automated testing into CI, benefits can include:
- enforcing the discipline of creating and running frequent automated tests
- immediate feedback on the impact of a team member’s changes on the entire system
- software metrics generated from automated tests and CIs (such as code coverage metrics, code complexity, and feature completeness) focus developers on developing high-quality functional code and help develop dynamism and commitment to the development team
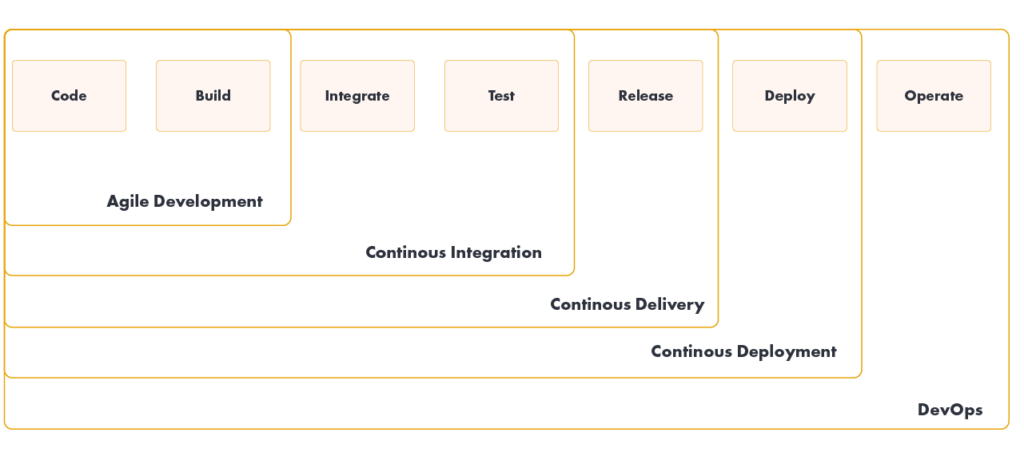
Continuous Integration / Continuous Delivery – differences
Continuous integration usually refers to integrating, building, and testing code in a development environment. This is what Continuous Delivery (CD) is all about, dealing with the final steps required for a production implementation.
Continuous Delivery is based on the following principles:
- the software can be deployed throughout its life cycle
- the team’s priority is to keep the software in continuous implementation
- anyone can get fast, automated feedback on the production readiness of their systems every time someone makes changes to them
- upon request, you can perform automatic deployment of any software version in any environment
Continuous Delivery is sometimes confused with Continuous Deployment. Continuous deployment means that every change goes through the CI pipeline and automatically goes into production, resulting in multiple production rollouts every day. Continuous delivery simply means that frequent deployments are possible, but you don’t have to do it automatically, usually due to companies preferring a slower deployment rate. Use continuous delivery to perform continuous deployment.
The main advantages of continuous delivery are:
- reduced deployment risk: as smaller changes are implemented, there are fewer bugs and easier to fix when a problem arises.
- credible progress: Many people track progress by keeping track of the work they have done. If “done” means “developers declare it’s done,” this is far less reliable than if deployed in a production (or production-like) environment.
- user feedback: The biggest risk with any software effort is that it will eventually create something that is not usable to the end user. The sooner and more frequently the end-user gets working software, the faster feedback is received to the software development team.
Continuous integration / Continuous integration – an inevitable reality
The idea of continuous integration is becoming more and more common as one of the main elements of the software development and project management process.
It seems that CI not only helps to integrate the software, but also somehow integrates the people who co-create the software. As it turns out, CI has a large impact on the quality and speed of the delivered software, which has a significant impact on how end customers perceive this software and its developers.
It is worth using continuous integration and it is worth improving this process every day – for the benefit and satisfaction of the teams that create better and better IT systems, and for the common satisfaction of our customers.