
Why Is Implementation So Important In The Software Development Process?
23 June 2021

The implementation phase plays the most important role in the software development process. It is at this stage that the physical source code of the system being built is created. Programmers code the IT system on the basis of the collected requirements and the developed project documentation. They are based on experience and proven software development techniques.
Implementation plan
The goals set in the implementation phase are:
- Defining the organization of the source code of the developed software in terms of the implementation of subsystems organized in layers.
- Implementing classes and objects in terms of components (source files, binaries, executables and others).
- Conducting unit tests of the developed components.
- Integrating parts of the source code developed by individual programmers (or teams) into an executable system.
The Implementation Discipline limits its scope to how each class is to be unit tested. System and integration testing are described in the discipline Test.
Implementation is related to other stages of building information systems:
- The Requirements stage describes how to present the requirements that the implementation should meet in the use case model.
- The Analysis and Design stage describes how to develop a system design model. The design model represents the basic input for the implementation stage.
- The Testing stage describes how to integrate each build into integration testing during system integration. It also describes how to test the system to verify that all requirements have been met, and how defects are detected and reported.
- The Environment stage describes how to develop and maintain information used during implementation, such as a process description, design guidelines, and programming guidelines.
- The Deployment Discipline describes how to use the implementation model to create and deliver code to the end customer.
- The Project Management discipline describes how to best plan a project. Important aspects of the planning process are iteration plans, change management, and defect tracking systems.
Flow of the implementation phase
The implementation phase can be broken down into several steps as follows:
- Building an implementation model.
- Integration planning.
- Implementation of components.
- Integration of subsystems and system.
Building an implementation model
The purpose of this step is to ensure that the implementation model is organized in such a way that the development of components and the compilation process are as conflict-free as possible. A well-organized model will prevent problems with configuration management and will allow you to build a product with appropriate elements integrated with each other.
At this stage, the software architect is responsible for developing the structure of the implementation model. The software architect’s experience must also include experience of system level integration. You need experience in software build management, configuration management, and experience with the programming language in which the components to be integrated are written. As integration automation will be handled by the system integrator role, the software architect does not need to be an expert in scripting or integration automation, but some knowledge of the subject will often help your software build flow smoother.
The structuring of the implementation model should occur in parallel with the evolution of other aspects of the architecture; Failure to take this into account at an early stage of the architectural process may lead to poor organization of the source code structure and may hinder the process of implementing and building an infromatic system. In the worst case, a poorly organized implementation model can significantly hamper parallel software development by the development team.
The purpose of building an implementation model is:
- Determining the structure of the source code of the system being built.
- Assignment of responsibilities for a given subsystem and its content.
When building an implementation model, the following steps can be distinguished:
- Creating an initial structure for the implementation model.
- Adaptation of the implementation subsystem.
- Defining dependencies between subsystems.
- Determining how to treat executables (and other derived objects).
- Determining how to treat test suites.
- Implementation view updated.
- Evaluation of the implementation model.
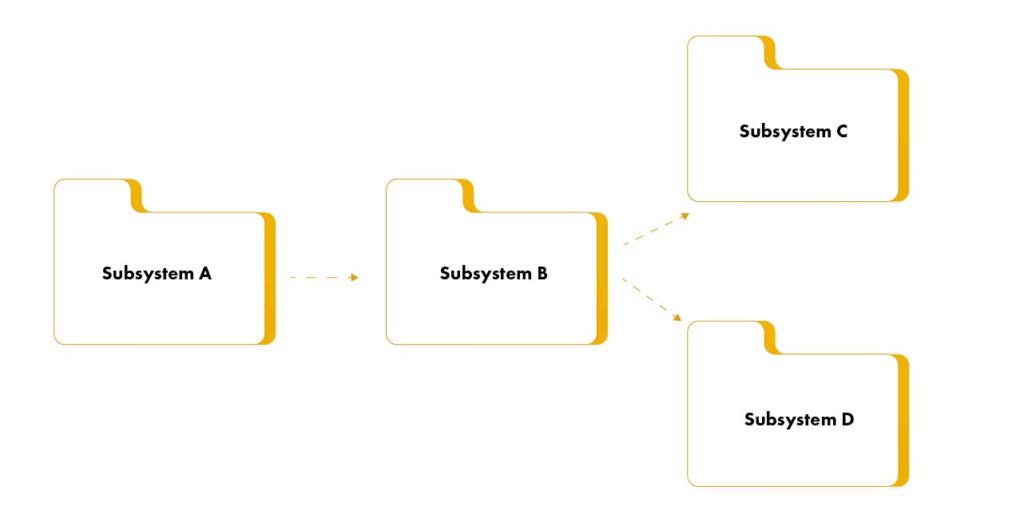
Creating the initial structure of the implementation model
Moving from “design space” to “implementation space”, start by reflecting the structure of the Design Model in the Implementation Model.
The development packages will have the appropriate implementation subsystems which will contain one or more components and all related files needed to implement the component. The mapping from the Design Model to the Deployment Model may change as each Deployment Subsystem is assigned to a specific layer in the architecture. Note that both the classes and possibly the design subsystems in the design model map to the components in the implementation model – though not necessarily one-to-one.
Customize the Implementation Subsystem
Adapt the structure of the implementation model to reflect the organization of the team or the limitations of the implementation language.
You must decide whether to reorganize the subsystems by addressing minor issues with your implementation environment. Below are some examples of such issues. Note that if there is a decision to change the organization of the implementation subsystems, you must also decide whether to go back and update the design model or let the design model differ from the implementation model.
- Organization of the development team. The structure of the subsystem must allow several programmers or a team of programmers to run in parallel without too much overlapping and disturbing. It seems advisable to have one and only one team for each implementation subsystem. This means that it is possible to break a given subsystem into multiple parts (if it is large) and assign these parts to be implemented by multiple development teams, especially if the teams have different cycles / sprints defined.
- Type declarations. As you implement it, you may realize that a subsystem has to import components from another subsystem because the type is declared in that subsystem. In this situation, it may generally be a good idea to extract the type declaration into a separate subsystem.
- Existing code and system components. You may need to include existing code, a reusable component library, or products off the shelf. If they have not been modeled in the project, add them to the implementation model.
- Dependency Customization. A circular dependency is a relationship between two or more modules that are directly or indirectly dependent on each other. This can be avoided by applying design patterns such as the observer pattern.
Define dependencies between subsystems
For each subsystem, you must determine which other subsystems are dependent. This can be done for entire sets of subsystems, allowing all subsystems in one tier to import all subsystems at a lower tier.
The layered structure of subsystems is usually shown in component diagrams.
Specifying how to treat executables (and other derived objects)
Executables (and other derived objects) are the result of applying a compilation process to an implementation subsystem (or subsystems) or parts of it, and so they logically belong to the implementation subsystem. However, the software architect, working with the configuration manager, will have to decide which configuration item structure to apply to the implementation model.
Specify how to treat test suites
The purpose of this step is to determine how to organize the test artifacts in the implementation model.
In general, test components and test subsystems are not treated significantly differently from other software developed. However, test components and subsystems are typically not part of the system deployed and are often not delivered to the customer. Separate test subsystems (intended for testing above the unit test level) should be treated in the same way as other implementation subsystems – as separate configuration items.
Update implementation view
The purpose of this step is to update the implementation view in a software architecture document.
The implementation view is described in the “Implementation View” section of the software architecture document. This section contains component diagrams that show the layers and the affiliation of implementation subsystems to their respective layers, as well as the dependencies between subsystems.
Evaluate the implementation model
The purpose of this step is to check if the implementation model meets the guidelines and the list of checkpoints for instance:
- Interfaces and dependencies between components have been defined.
- The workload for the Implementation Team is balanced; potential bottlenecks have been identified and work has been redistributed, and contingency plans have been created to allow critical work to be redistributed if the initial work allocation becomes imbalanced.
- There are no instances of dependencies crossing more than one layer boundary.
- Unnecessary dependencies on lower-layer components have been eliminated.
- The impact of necessary dependencies on lower layer components have been reduced by letting components in middle layers re-export interfaces from components in lower layers.
- The number of layers is no more than seven (plus or minus two), or there is a well-understood reason why more layers exist.

Component Implementation
In this step, developers write source code, adapt existing components, compile, link, and perform unit tests, implementing the classes in the design model. If defects are found in the design, the developers provide feedback on the corrections in the design.
Developers also fix code defects and run unit tests to verify changes. The code is then reviewed to assess quality and compliance with the Development Guidelines.
The developer steps above are typically performed by one person. Source code reviews are best performed by a small team of team members with different functions, typically older team members with more experience of common problems and pitfalls encountered in a programming language. Special expertise may be required in the problem area. Expertise in specific algorithms or programming techniques may also be required.
The purpose of the component implementation stage is to create the source code in accordance with the design model described in the design documentation of the system being created.
As part of this stage, programmers perform the following activities:
- Operation implementation
- Implementation of state machines
- Implementation of design patterns
- Implementation of relationships between classes
- Implementation of class attributes
- Provide feedback on system design
- Source code quality assessment
There is no strict order between the steps above. Start deploying operations and implement associations and attributes as needed to build and run operations.
Note: The implementation and modification of components takes place in the context of project configuration management. Programmers are expected to operate in their own programming workspaces, where they perform programming work. This workspace creates source code and uploads it to the common source code repository.
Read also: What is Continuous Integration?
Source codes are created and placed as part of configuration management, or modified through the usual check out, edit, build, unit test, and check in cycle. After completing a certain set of components (defined by one or more Work Orders and required for the upcoming build), the developer delivers (see Action: Submit Changes) the related new and modified components to the source code repository for integration with the work of other developers.
Developers should follow the programming guidelines when implementing classes.
The foreground for implementation are classes with public operations, attributes, and associations. Be aware that not all public operations, attributes, and bindings are defined during the design phase.
The second basis for implementation are use case realizations that show how classes and objects work together to execute a use case specified when developing requirements for the system being built.
Operation implementation
To implement the operations, the developer will do the following:
- determines the algorithm
- selects data structures suitable for algorithms
- define new classes and operations as needed
- encodes the operation
Many operations are so simple that they can be implemented directly from the operation and its specification.
Non-trivial algorithms are needed primarily for two reasons: to implement complex operations for which a specification is provided, and to optimize operations for which a simple but effective algorithm is used as the definition.
The choice of algorithms is related to the choice of the data structure they are working on. Many of the implementation data structures are container classes, such as arrays, lists, queues, stacks, and their variations. Most object-oriented languages and development environments provide class libraries with these kinds of reusable components.
For example, you can find new classes holding intermediate results, and you can add new low-level operations to the class to break down a complex operation. These operations are often private within the class, that is, invisible outside the class itself.
Implementation of the state machine
Developers often use the “State” design pattern to implement a state machine.
Implementation of class relationships
Most object-oriented languages and development environments provide class libraries with reusable components to implement various kinds of class relationships.
Implementation of Attributes
The class attributes can be implemented by programmers in the form of built-in types of primitive variables or as defined complex types – classes.
Provide feedback on system design
If a design error is detected in any of the steps, programmers provide feedback on the need for a design revision.
Assessing the quality of the source code
Before you start unit testing, you need to do some checks:
- compile source code by setting the appropriate compiler warning level
- own code review
- static code analysis (using appropriate tools)

Prepare and run unit tests
A unit test is a method of testing the software being developed by performing tests that verify the correct operation of individual program elements (units) – e.g. methods or objects in object-oriented programming or procedures in procedural programming. The tested part of the program is subjected to a test that executes it and compares the result (e.g. returned values, object state, exceptions raised) with the expected results – both positive and negative (failure of the code in certain situations can also be tested).
The advantage of unit tests is the ability to perform fully automated tests on the modified program elements on an ongoing basis, which often allows you to catch an error immediately after it appears and quickly locate it before introducing an incorrect fragment to the program. Unit testing is also a form of specification.
Integration of subsystems and system
Integration work is usually highly automated. A common strategy is to perform automatic builds / builds and automated tests (usually at the unit level), which allows frequent status information from the build process.
Read also: What is Continuous Integration?
Everything as code
Software source code is the main and most important output of the software development process. The source code says a lot about the quality of the requirements (functional and non-functional) collected during the system analysis process. The source code also says a lot about the level of experience of the development team. It is therefore worth appreciating the work put into the continuous improvement of the software development process as well as increasing the experience of programming teams.
The approach to how software’s source code is dealt with seems to extend to other aspects of software. This approach can be called “everything as code”. So source code is important and should be approached accordingly for its creation, storage, documentation and further development.